
2019 was a big year for all of Data Science.
Companies all over the world across a wide variety of industries have been going through what people are calling a digital transformation. That is, businesses are taking traditional business processes such as hiring, marketing, pricing, and strategy, and using digital technologies to make them 10 times better.
Data Science has become an integral part of those transformations. With Data Science, organizations no longer have to make their important decisions based on hunches, best-guesses, or small surveys. Instead, they’re analyzing large amounts of real data to base their decisions on real, data-driven facts. That’s really what Data Science is all about — creating value through data.
This trend of integrating data into the core business processes has grown significantly, with an increase in interest by over four times in the past 5 years according to Google Search Trends. Data is giving companies a sharp advantage over their competitors. With more data and better Data Scientists to use it, companies can acquire information about the market that their competitors might not even know existed. It’s become a game of Data or perish.
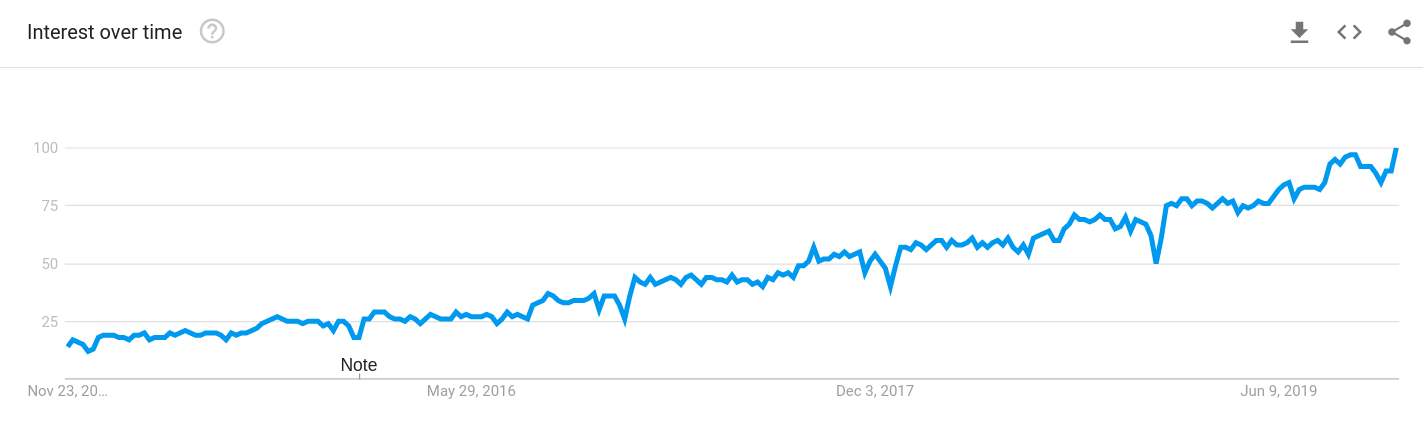
Google search popularity of “Data Science” over the past 5 years. Generated by Google Trends.
In today’s ever-evolving digital world, staying ahead of the competition requires constant innovation. Patents have gone out of style while Agile methodology and catching new trends quickly is very much in.
Organizations can no longer rely on their rock-solid methods of old. If a new trend like Data Science, Artificial Intelligence, or Blockchain comes along, it needs to be anticipated beforehand and adapted quickly.
The following are the 4 hottest Data Science trends for the year 2020. These are trends which have gathered increasing interest this year and will continue to grow in 2020.
(1) Automated Data Science
Even in today’s digital age, Data Science still requires a lot of manual work. Storing data, cleaning data, visualizing and exploring data, and finally, modeling data to get some actual results. That manual work is just begging for automation, and thus has been the rise of automated Data Science and Machine Learning.
Nearly every step of the Data Science pipeline has been or is in the process of becoming automated.
Auto-Data Cleaning has been heavily researched over the past few years. Cleaning big data often takes up most of a Data Scientist’s expensive time. Both startups and large companies such as IBM offer automation and tooling for data cleaning.
Another large part of Data Science known as feature engineering has undergone significant disruption. Featuretools offers a solution for automatic feature engineering. On top of that, modern Deep Learning techniques such as Convolutional and Recurrent Neural Networks learn their own features without the need for manual feature design.
Perhaps the most significant automation is occurring in the Machine Learning space. Both Data Robot and H2O have established themselves in the industry by offering end-to-end Machine Learning platforms, giving Data Scientists a very easy handle on data management and model building. AutoML, a method for automatic model design and training, has also boomed over 2019 as these automated models surpass the state-of-the-art. Google, in particular, is investing heavily in Cloud AutoML.
In general, companies are investing heavily in building and buying tools and services for automated Data Science. Anything to make the process cheaper and easier. At the same time, this automation also caters to smaller and less technical organizations who can leverage these tools and services to have access to Data Science without building out their own team.
(2) Data Privacy and Security
Privacy and security are always sensitive topics in technology. All companies want to move fast and innovate, but losing the trust of their customers over privacy or security issues can be fatal. So, they’re forced to make it a priority, at least to a bare minimum of not leaking private data.
Data privacy and security has become an incredibly hot topic over the past year as the issues are magnified by enormous public hacks. Just recently on November 22, 2019, an exposed server with no security was discovered on Google Cloud. The server contained the personal information of 1.2 Billion unique people including names, email addresses, phone numbers, and LinkedIn and Facebook profile information. Even the FBI came in to investigate. It’s one of the largest data exposures of all time.
To continue reading this article click here.
You must be logged in to post a comment.



Pingback: The 4 Hottest Trends in Data Science for 2020 – Machine Learning Times – NikolaNews
Pingback: The 4 Hottest Trends in Data Science for 2020 – Machine Learning Times – Bitfirm.co
Pingback: The 4 Hottest Trends in Data Science for 2020 – Machine Learning Times – machine learning & data science news – The Predictive Analytics Times | Prometheism Transhumanism Post Humanism
Pingback: Trends in Data Science for 2020 | BLOCKGENI