

The detection of fraudulent credit card transactions is an ideal candidate for the application of machine learning technology. However, in order to learn how to spot attempted fraud, such a system needs someone to tell it which historic transactions were OK, and which were not.
Excerpted from The AI Playbook: Mastering the Rare Art of Machine Learning Deployment,1 by Eric Siegel (6 February 2024), published by The MIT Press.
Scott Zoldi fights crime across the globe. His superpower is data – and an unprecedented, innovative process to amass that data.
He’s got his work cut out for him. Every day, hordes of criminals work to exploit systemic vulnerabilities in how you and I shop. Their relentless work chips away at the very integrity of consumer commerce at large.
I’m talking about fraud. Crooks obtain your card details so that they can perform a transaction and make off with the spoils. In 2021, payment card fraud losses reached $28.58 billion worldwide.2 The United States suffers more than any other country, accounting for more than a third of that loss. To make matters worse, fraud increased during the pandemic, in part due to the increase in “card not present” virtual transactions. Some called it the “scamdemic”.
Scott is FICO’s chief analytics officer. He oversees the world’s largest-scope anti-fraud operation. Day in and day out, his product Falcon screens all of the transactions made with most of the world’s credit and ATM cards – 2.6 billion cards globally. With Falcon, banks and other financial institutions can instantly block suspicious purchases and withdrawals.
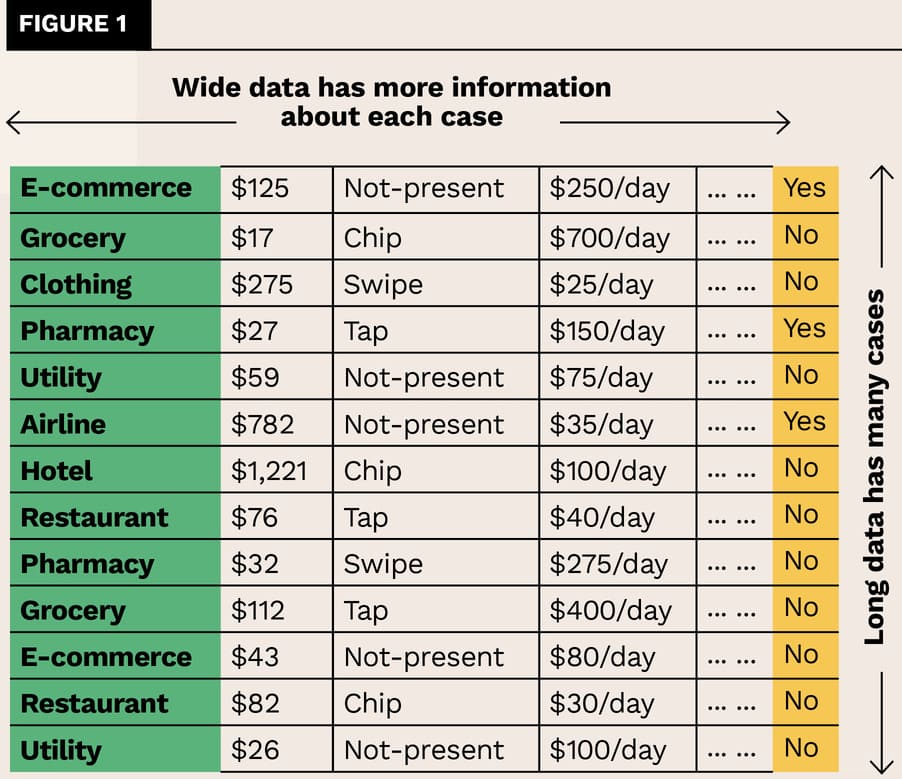
This capability hinges on machine learning, and it demands an impressive dataset. A fraud-detection model must predict well, striking a tricky balance so that it recognises a lot of fraud and yet does so without incurring too many false positives.3 To this end, the data must fulfil exacting requirements. If you visualise the data as a simple table, just a big spreadsheet, it must be long, wide, and labelled. Here’s what I mean:
Such a data set sounds almost impossible to acquire. It could only be sourced from multiple banks across the globe. And even if you somehow convinced these institutions to cooperate and obtained a representative slew of example transactions, the fraudulent ones aren’t going to label themselves.
To obtain this data, Scott’s got to align the stars.
Scott has a PhD in theoretical physics from Duke University. And he’s formed a team of 70 more people with PhDs. Together, they generate the world’s de facto system for detecting fraudulent card transactions. You, I, and most people with payment cards are relying on them.
Scott’s anti-fraud operation isn’t what FICO is most widely known for. Along with another one of his teams, Scott also oversees this country’s most famous deployed model: the FICO Credit Score. Your FICO Score determines your power to borrow. It’s the most widely used credit score in the United States, employed by the vast majority of banks and credit grantors. It’s a household name, and many understandably feel that their FICO Score is a central part of their identity as a consumer.
But FICO’s fraud detection, which is normally invisible to us as consumers, affects us much more often. Named Falcon, this product is the biggest part of FICO’s software business and affects most of us almost every day, every time you use your card. FICO evaluates financial power by day, and fights financial crime by night.
To meet this responsibility, it’s important that the Falcon team gets the data it needs – some long, wide, and labelled data. To do so, it collects data from across a global network of banks.
This reliance on inter-enterprise data, collected from multiple companies, is atypical. Ordinarily, an ML project serves only the enterprise running the project. For such a project, internal data suffices, since the company has been tracking the very operations that the project aims to improve. In contrast, FICO isn’t a bank. It doesn’t process card transactions. Rather, it holds a rare, globally central, entrusted role across banks.
In 1992, Falcon was born of a radical move by a small group of banks. They decided to cooperate, rather than only compete. At the time, a tremendous portion of all credit card transactions – almost 1 per cent – were fraudulent. The fraud rate was only growing and threatened the entire industry. This looming crisis convinced financial institutions to overcome their raw capitalistic instincts and follow a call to arms for the universal good: to collaborate to fight crime, improve transaction integrity, and cut losses. Led by a company called HNC Software, they joined their data together, thereby multiplying their power to train fraud-detection models. Ten years later, FICO acquired HNC Software – and both Falcon and Scott Zoldi along with it.
Since then, Falcon’s consortium has grown to more than 9,000 banks globally, all continually sending in anonymised card transaction details. FICO receives about 20 billion records, amounting to terabytes of raw data, each month, a petabyte every five years.
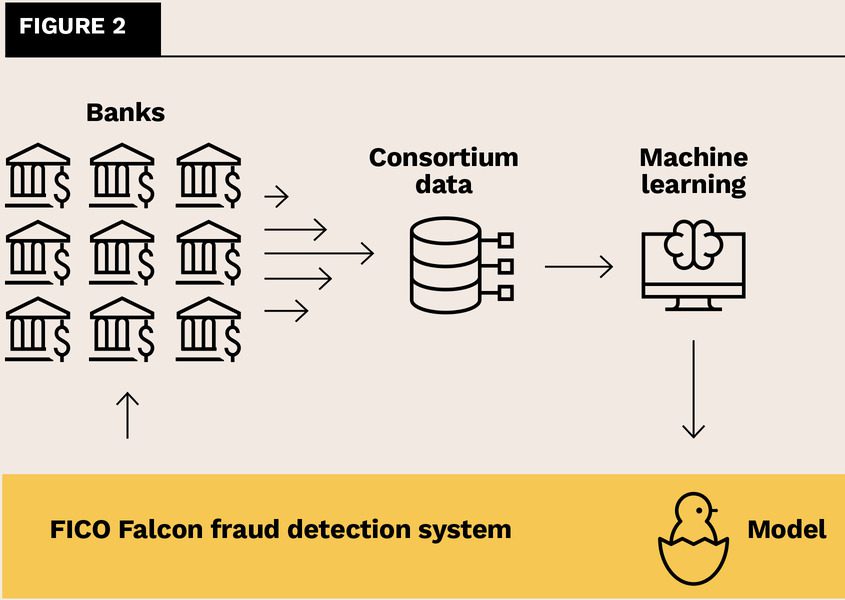
Banks provide data to develop Falcon’s fraud-detection model and Falcon deploys that model for each bank.
Banks can’t benefit from Falcon without contributing to it. To be a FICO customer that uses Falcon, you must also join the consortium and share your data. Falcon has become so standard that, despite its cooperative nature, it’s a competitive necessity. To hold their position in the payment card market, banks need Falcon’s best-in-class fraud detection, which they can access only by cooperating. In the end, this levels the playing field. Even the smallest bank can deploy the very best fraud-detection model.
In addition to tons of examples, Falcon’s training data needs another ingredient: labels that correspond with the model’s intended output. Each example transaction that makes for a row of data is incomplete until designated as either fraudulent or not fraudulent. Those labels will guide model training to do its job: generate a model that can discern positive cases from negative cases.
Only humans can provide the labels. For detection, we don’t get to benefit from “time will tell”, as we do when predicting a future event. Time has told whether a user responded when shown a certain ad or whether a debtor has defaulted. In those cases, we get the label “for free”. But for detecting a qualitative attribute for each case, such as whether it is fraudulent, each training example’s label can only be determined by a person.
Manual labelling is labour-intensive and expensive. The expense especially racks up when it requires subject matter experts, such as doctors for establishing whether each example indicates a certain medical diagnosis.
On the other hand, problems that don’t require special expertise, such as labelling traffic lights within images for an autonomous-driving project, can be outsourced on “crowd labour” platforms like Amazon Mechanical Turk for as little as a penny per case. But there’s a dark side: their largely unregulated working conditions “offer a bleak glimpse of what could come for a growing digital underclass”, according to Vocativ. Marketplace 4 calls this “the new factory floor of the digital age”.
To make matters worse, fraud detection requires an immense number of labelled transactions, because positive ones are rare. If the fraud rate is 0.1 per cent and you want the data to include at least 10,000 positive cases, then you need to label 10 million cases as to whether each is positive or negative.
Don’t fret! Falcon’s training data manages to sidestep this costly bottleneck by relying on what consumers do naturally. With card fraud, if the consumer sees an erroneous charge, they complain. We cardholders and our banks are, in effect, already doing all the grunt work to label many cases of fraud in the course of just living our lives.
A key reason that this approach works is that, with card fraud, banks can afford to learn the hard way. Since the detection system is imperfect, it allows some fraudulent transactions to go through. This generates a positive training case if the cardholder later complains about the unauthorised charge, even though it’s then typically too late to prevent the fraudster’s crime. The cost is absorbed by the bank, but the overall cycle is economically satisfactory. No humans were substantially harmed in the process of this data creation.
In other domains, you can’t do it that way. The missed, uncaught cases – false negatives – aren’t nearly as allowable for an autonomous vehicle that would drive through a red light or a medical system that would miss a diagnosis. In those domains, you often can’t avoid the need for additional manual work labelling many examples.
This “organic” labelling process for fraud detection, wherein people are essentially “following the money”, prioritises bigger cases of fraud over smaller cases. FICO treats only adjudicated fraud as positive cases, where the cardholder has formally certified that the transaction was fraudulent (whether it was them or the bank who noticed it in the first place). This means that suspected cases that never get adjudicated aren’t labelled as positive in the training data, even if the bank had to write off the charge. Since folks tend to bother with adjudication more for larger-value cases of fraud, lower-cost fraud is less often correctly labelled and is therefore effectively deprioritised by Falcon’s model. And that’s tolerable, since the false negative cost is lower for them.
On top of this manual labelling, many other positive cases are passively labelled – those that Falcon has spotted automatically. A bank using Falcon blocks an attempted fraudulent transaction and the cardholder might never even hear about it. This is almost a circular process, since that positive example will then serve to train an updated model for Falcon, which identified the positive case in the first place. However, once again, natural cardholder reactions help correct the data. If Falcon was wrong – if it is a false positive – then the cardholder, whose legitimate attempt to transact was blocked, will often take action to get it approved and the case will wind up as negative in the training data. In that way, what the model got wrong will serve to improve the next version of the model.
Altogether, this provides plenty of positive examples for Scott’s team. The number of labelled cases of fraud that they end up with approaches one million.
I consider Falcon one of the world’s most successful and widely impactful commercial deployments of ML. It screens all the transactions for 2.6 billion payment cards worldwide. That’s two-thirds of the world’s cards, including about 90 per cent of those in the United States and the United Kingdom. Seventeen of the top 20 international credit card issuers, all of the United States’ 100 largest credit-card issuers and 95 of the United States’ top 100 financial institutions, use Falcon.
Since its introduction, Falcon has reduced card fraud losses by more than 70 per cent in the United States. With the United States currently suffering around $10 billion in annual fraud losses, that reduction is saving that country alone something in the vicinity of $20 billion per year.
For a detailed example stepping through the arithmetic to show how much money a bank might save by deploying a fraud detection model, see my MIT Sloan Management Review article “What Leaders Should Know About Measuring AI Project Value”.5 For more reading on payment card fraud detection in general, and FICO Falcon in particular, see this collection of citations.6
This article is excerpted from the book, The AI Playbook: Mastering the Rare Art of Machine Learning Deployment, with permission from the publisher, MIT Press. It is a product of the author’s work while he held a one-year position as the Bodily Bicentennial Professor in Analytics at the UVA Darden School of Business. For a complete bibliography for this article, see this PDF.7
About the Author
 Eric Siegel, PhD, is a leading consultant and former Columbia University professor who helps companies deploy machine learning. He is the founder of the long-running Machine Learning Week8 conference series and its new sister, Generative AI Applications Summit,9 the instructor of the acclaimed online course “Machine Learning Leadership and Practice – End-to-End Mastery”,10 executive editor of The Machine Learning Times,11 and a frequent keynote speaker.12 He wrote the bestselling Predictive Analytics: The Power to Predict Who Will Click, Buy, Lie, or Die,13 which has been used in courses at hundreds of universities, as well as The AI Playbook: Mastering the Rare Art of Machine Learning Deployment. Eric’s interdisciplinary work bridges the stubborn technology / business gap. At Columbia, he won the Distinguished Faculty award when teaching the graduate computer science courses in ML and AI. Later, he served as a business school professor at UVA Darden. Eric also publishes op-eds on analytics and social justice.14
Eric Siegel, PhD, is a leading consultant and former Columbia University professor who helps companies deploy machine learning. He is the founder of the long-running Machine Learning Week8 conference series and its new sister, Generative AI Applications Summit,9 the instructor of the acclaimed online course “Machine Learning Leadership and Practice – End-to-End Mastery”,10 executive editor of The Machine Learning Times,11 and a frequent keynote speaker.12 He wrote the bestselling Predictive Analytics: The Power to Predict Who Will Click, Buy, Lie, or Die,13 which has been used in courses at hundreds of universities, as well as The AI Playbook: Mastering the Rare Art of Machine Learning Deployment. Eric’s interdisciplinary work bridges the stubborn technology / business gap. At Columbia, he won the Distinguished Faculty award when teaching the graduate computer science courses in ML and AI. Later, he served as a business school professor at UVA Darden. Eric also publishes op-eds on analytics and social justice.14
References



