
By: Rachel Thomas
Originally published in fast.ai, April 29, 2018
There is a powerful technique that is winning Kaggle competitions and is widely used at Google (according to Jeff Dean), Pinterest, and Instacart, yet that many people don’t even realize is possible: the use of deep learning for tabular data, and in particular, the creation of embeddings for categorical variables.
Despite what you may have heard, you can use deep learning for the type of data you might keep in a SQL database, a Pandas DataFrame, or an Excel spreadsheet (including time-series data). I will refer to this as tabular data, although it can also be known as relational data, structured data, or other terms (see my twitter poll and comments for more discussion).
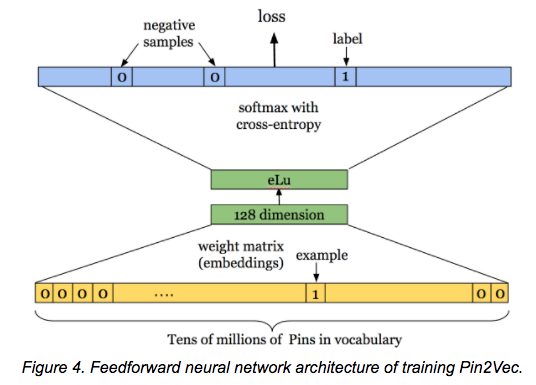
From the Pinterest blog post ‘Applying deep learning to Related Pins’
Tabular data is the most commonly used type of data in industry, but deep learning on tabular data receives far less attention than deep learning for computer vision and natural language processing. This post covers some key concepts from applying neural networks to tabular data, in particular the idea of creating embeddings for categorical variables, and highlights 2 relevant modules of the fastai library:
To continue reading this article in fast.ai, click here.
About the Author:

Rachel Thomas was selected by Forbes as one of 20 Incredible Women in AI, earned her math PhD at Duke, and was an early engineer at Uber. She is a professor at the University of San Francisco and co-founder of fast.ai, which created the “Practical Deep Learning for Coders” course that over 100,000 students have taken. Rachel is a popular writer and keynote speaker. Her writing has been read by over half a million people; has been translated into Chinese, Spanish, Korean, & Portuguese; and has made the front page of Hacker News 7x.


