

(Image Source: Pexels)
For today’s leading deep learning methods and technology, attend the conference and training workshops at Deep Learning World Las Vegas, June 16-20, 2019.
When eBay was looking for a cutting edge machine learning solution that could train a large scale visual model to recognize hundreds of millions of product images across over 10,000 categories, so that eBay customers could perform a quick image search and find the perfect product in seconds, they needed a powerful hardware accelerator. They used Google Cloud TPU Pods that actually gave them a 10X reduction in training time, helping them accomplish in 4 days what earlier was taking the 40 days!
This is a game changer—the dramatic increase in training speed not only allows us to iterate faster but also allows us to avoid large up-front capital expenditures.
That’s what eBay had to say about the TPUs. Incepted in 2013 and primarily used in-house by Google for many years, TPU’s or Tensor Processing Units finally became open to the public in the form of a beta version in the cloud. Today, they pose a sizeable competition to the incumbent GPU leader Nvidia.
Until now, this was a forte occupied by GPUs or Graphic Processing Units that deploy thousands of ALUs in a single processor, allowing you to perform thousands of parallel computations simultaneously, making GPUs capable of extensive machine learning training and inferencing.
GPUs have been the leader in deep learning for long now and still reign over the market, with the 6 biggest tech giants – Amazon, Alibaba, Facebook, Microsoft, TenCent and Baidu – still buying GPUs from Nvidia.
TPUs however, are quickly radicalizing the market, considering they are already turning heads in a big way, despite not being a full-fledged for-sale product yet. So which one is really the better choice for your next machine learning project? Should you choose a GPU or a TPU to train your machine learning models? Let’s do a detailed analysis of both to answer that question for you.
When it comes to training neural networks, one word rules them all – data. The larger the data sets and the more the data, the higher will be the accuracy of your machine learning inferences or predictions. If you’re developing speech recognition software, your deep neural networks need to be trained for a massive number of sounds.
For image recognition, you need to train for millions of floating point values depending on the number of pixels in the picture. With high-resolution becoming the norm, something like a 1920×1080 image would mean 2,073,600 pixels. Training your neural networks to process such a high number of pixels and perform an accurate prediction, all in a matter of seconds, is no mean feat.

Source: Pixabay
To train your system for such humongous datasets, you need processing hardware with some robust machine learning capabilities. The software they use, the memory on them, their bandwidth, TFLOPS performance, power, number of cores and pods are some of the things that determine the efficacy of your processor in accurate training and inferencing.
So which one of the two – GPU and TPU – offer better performance in these areas? Let’s analyze.
GPU
GPUs are extremely efficient at matrix multiplication, which basically forms the core of machine learning. The strength of GPU lies in data parallelization, which means that instead of relying on a single core, as CPUs did before, a GPU can have many small cores.
A single GPU can have thousands of Arithmetic Logic Units or ALUs, each performing a parallel computation to return a higher throughput faster, thus running complex computations in a short span of time. This makes GPUs highly suitable for performing complex matrix multiplications in a short span of time.
Nvidia’s most powerful Tesla V100 data center GPU for instance, features 640 tensor cores and 5,120 CUDA cores. This means that at the peak of its tensor throughput, it can produce a staggering 125 TFLOPS. Thanks to that, it offers a dramatically high precision rate resulting in a tighter machine learning system with very high accuracy.
Even if in your project, you might not necessarily use a Tesla V100, you now have a general idea of how robust and precise the GPU performance can be when it comes to analyzing extremely large datasets and accurately train your machine learning model.
In terms of memory and cache, the best GPUs offer a shared memory sub system that can be shared across all different cores of the GPU. The L1 cache ensures swift performance reducing latency and optimizing memory usage.
GPUs are optimized for the CUDA software technology that was specifically designed for parallel computing and independent multi-threading operations. This offers ample flexibility for the programmers and keeps things simple.
TPU
When it comes to machine learning and deep neural networks, Google is definitely the leader of the pack. The fact that Google Photos accurately identifies the photos of one person from the time they were just a day old to when they were playing soccer in the park, or how Gmail almost always has the perfect auto-responses to emails, is a testament to Google’s deep learning prowess.
And when the Google AI beat human champions in the Chinese board game Go, an irreversible current of AI changed the world for good. While Google itself used Nvidia GPUs on an Intel Xeon CPU for the longest time, they have now really truly jumped into the hardware market with their custom made tensor processing units or TPUs.
Google has been using these TPUs in-house on their applications like Google Photos, Google Translate, Google speech recognition, Gmail, Google assistant and many more for a few years now.

They recently made it possible for other developers to use the TPU by renting it through the cloud. They are still not planning on selling the hardware itself.
Built using 4 custom made ASICs or application-specific integrated circuit, specifically designed for machine learning using TensorFlow, TPUs offer a truly robust 180 TFLOPS of performance with 64GB of high bandwidth memory. This makes TPUs perfect for both training and inferencing of machine learning models.
Google’s ambition behind building a custom TPU was to shorten the training time of machine learning models and reduce the cost involved. Jeff Dean, team lead at Google Brain tweeted that their Cloud TPU can train a ResNet-50 model to 75% accuracy in just 24 hours.
Anantha Kanchrela, company head of software, self-driving at Lyft too said that ever since Lyft began working with Google cloud TPU, they have been ‘extremely impressed with their speed’. They can now do in hours what earlier took days.
In addition to accuracy and speed, the TPUs also offer a higher energy efficient than conventional processing chips, consuming much less watts and also reducing the heat generated. Being based on TensorFlow, the neural networks require very little code, making TPUs that much easier to deploy. The biggest advantage however, is cost.
So Which One Do You Choose For Training Your Deep Neural Net?
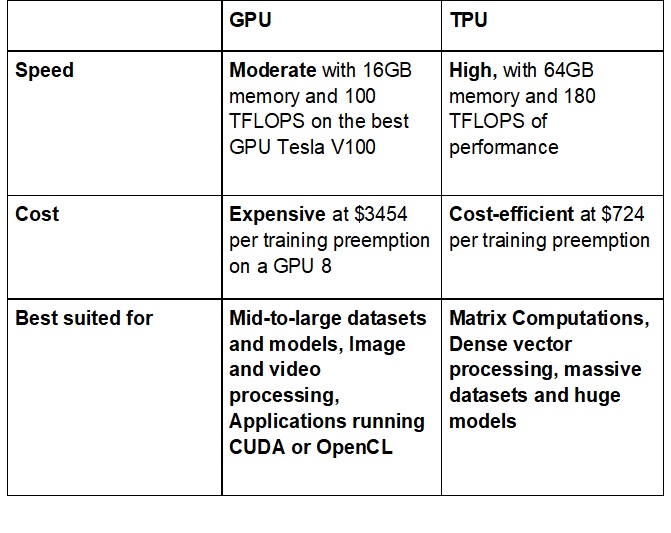
GPU has been the gold standard in graphics processing for a long, long time now, and has shown remarkable performance in machine learning. As stated in the beginning of this post, GPUs are still the chips being used by the biggest tech giants around the world. They can perform billions of calculations in seconds and train machine learning models to commendable accuracy. However, GPUs are expensive, very expensive.
TPUs have emerged as a disruptor when it comes to cost. They are a lot cheaper and easily available on the cloud. And don’t we all know how cost is one of the biggest concerns on any project.
In addition to that, TPUs exhibit immense improvements in speed and performance, making them a clear choice in the future. The scales are definitely tipping in the favor of TPUs therefore, and you may want to look at them before you dive headlong into your next ML project.
About Author:
 Gaurav Belani is a senior SEO and content marketing analyst at Growfusely, a content marketing agency that specializes in data-driven SEO. He has more than seven years of experience in digital marketing and loves to read and write about education technology, AI, machine learning, data science, and other emerging technologies. In his spare time, he enjoys watching movies and listening to music. Connect with him on Linkedin and Twitter @belanigaurav.
Gaurav Belani is a senior SEO and content marketing analyst at Growfusely, a content marketing agency that specializes in data-driven SEO. He has more than seven years of experience in digital marketing and loves to read and write about education technology, AI, machine learning, data science, and other emerging technologies. In his spare time, he enjoys watching movies and listening to music. Connect with him on Linkedin and Twitter @belanigaurav.
This content is restricted to site members. If you are an existing user, please log in on the right (desktop) or below (mobile). If not, register today and gain free access to original content and industry news. See the details here.



Notifications