
Originally published in Forbes
This is the third of a three-article series covering the business value of predictive AI, using misinformation detection as an example for illustration: article 1, article 2, article 3.
It’s an established practice, yet it still hasn’t been standardized. Predictive AI has been improving enterprise operations for decades, but there’s no broadly adopted process for assessing its potential value and deploying it accordingly.
Here’s the standard to live up to. The predictive model-valuation process should look something like this:
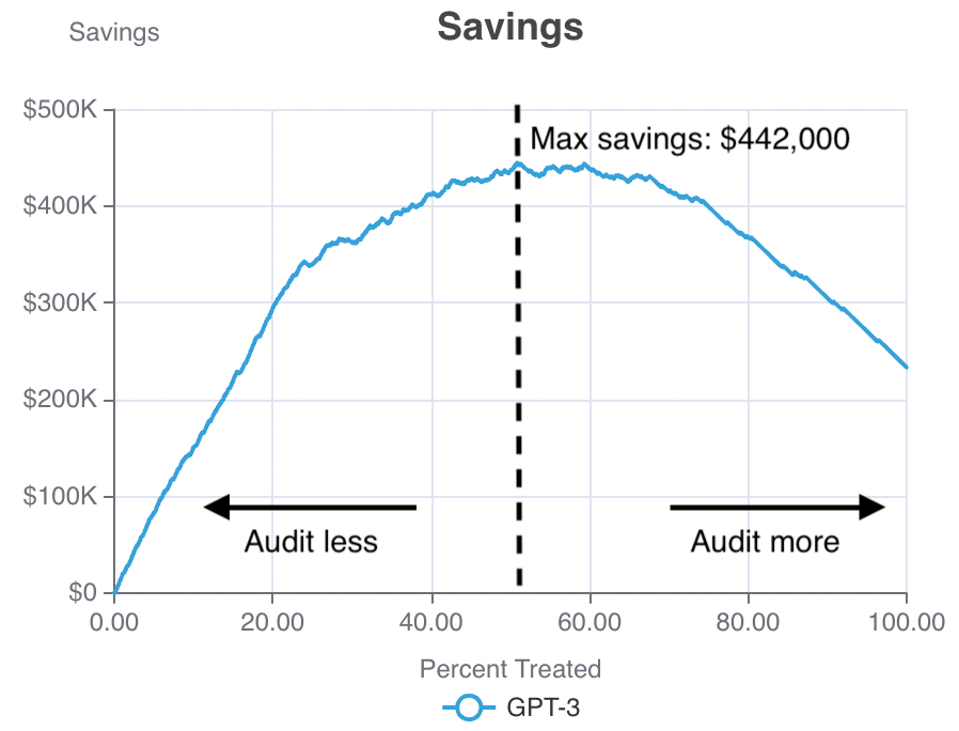
A savings curve for misinformation detection. The horizontal axis represents the portion of posts manually audited and the vertical axis represents savings. – ERIC SIEGEL
As I detailed in the first two articles of this series, this savings curve above plots action against value: The horizontal axis represents the number of social media posts manually screened as potential misinformation—as targeted by a predictive model—and the vertical axis represents the dollars saved.
This kind of view is not standard. Unfortunately, predictive AI projects rarely assess the potential value in terms of straightforward business metrics like profit and savings. This omission contributes to the high rate with which these projects fail to launch.
Business valuation must involve business particulars. The traditional way of doing things—evaluating predictive models only in terms of technical metrics, such as precision, recall and accuracy—is abstract, involving no particulars about how the business is meant to use the model. In contrast, valuating models in terms of business metrics hinges on incorporating business factors.
Here are the business factors behind the example savings plot shown above:
While the first two of these can be objectively established—based on the number of applicable posts per day and the cost of labor—the third is subjective, so there may be no definitive way to determine its setting.
Establishing the cost of each error is critical. By doing so we can bridge a precarious gap, moving from pure predictive performance to business KPIs. Analytics consultant Tom Khabaza has been telling us how important that is for a long time—ever since we called ML “data mining.” His Value Law of Data Miningstates, “There is no technical measure of [a model’s] value… The only value is business value.”
But sometimes it seems next to impossible to set the costs. Take medical diagnosis. If you mistakenly tell a healthy patient they’ve just had a heart attack, that’s bad. You can imagine the unnecessary stress, as well as the unnecessary treatments possibly administered. But if you mistakenly fail to detect a real heart attack, that’s worse. You let a serious condition go untreated. How much worse is a missed diagnosis in comparison to a positive misdiagnosis? A hundred times worse? Ten thousand times? Someone’s got to put a number on that and I’m glad it’s not me.
For many business applications of ML, we have it much easier. The misclassification costs are often self-evident, based on business realities such as the cost of marketing, the cost of fraud or the opportunity cost for each missed customer who would have responded if contacted.
But not always. Even spam detection can go wrong and cost you something immeasurable, such as a missed job—or even a missed date with someone you would have ended up marrying. A false positive means you may miss out on an important message, and a false negative means you have to manually filter spam out of your inbox. There’s no consensus on how to best determine the relative costs of these two, but whoever is behind your spam filter made that determination—if not intentionally and explicitly, then by allowing the system to effectively default to something arbitrary.
Sometimes decision makers must quantify the unquantifiable. They must commit to specific costs for misclassification errors—despite the subjectivity and ethical dilemmas. Costs drive the development, valuation and use of the model.
“Be sure to assign costs for FPs and FNs that are directionally better than just passively assuming the two costs are equal,” industry leader Dean Abbott told me, “even when you don’t have a truly objective basis for doing so.”
Imagine that a lawyer storms into the room, declaring, “We got slammed in the press over the weekend due to misinformation on our platform—it’s literally costing us!”
A nervous executive might respond, “Let’s boost the assumed cost of undetected misinformation from $10 to $30.”

The savings curve for misinformation detection with the false negative cost changed to $30. – ERIC SIEGEL
As you can see, the shape of the curve changed, shifting the point of maximal savings over to 74%. The curve is suggesting that the company inspect more posts—which makes sense, given the newly elevated value of identifying and blocking misinformation.
But it’s still subject to change. The $30 figure only came from the gut of the executive. It isn’t written in stone. In light of this fickleness, your only recourse is to accrue wisdom about how much of a difference further potential changes will make. As you and your colleagues deliberate the cost setting and try out different values, view how this curve’s shape changes. An intuitive understanding hinges on visualizing the story the curves tell and the degree to which that story changes across possible cost settings.
Here are your three takeaways from this story:
1) We must valuate predictive models in terms of business metrics.
2) We must view profit and savings curves to navigate deployment trade-offs.
3) We must view how the curve changes as we adjust business factors—those subject to change, uncertainty or subjectivity.
Follow me on Twitter or LinkedIn. Check out my website or some of my other work here.
About the author
Eric Siegel is a leading consultant and former Columbia University professor who helps companies deploy machine learning. He is the founder of the long-running Machine Learning Week conference series, the instructor of the acclaimed online course “Machine Learning Leadership and Practice – End-to-End Mastery,” executive editor of The Machine Learning Times and a frequent keynote speaker. He wrote the bestselling Predictive Analytics: The Power to Predict Who Will Click, Buy, Lie, or Die, which has been used in courses at hundreds of universities, as well as The AI Playbook: Mastering the Rare Art of Machine Learning Deployment. Eric’s interdisciplinary work bridges the stubborn technology/business gap. At Columbia, he won the Distinguished Faculty award when teaching the graduate computer science courses in ML and AI. Later, he served as a business school professor at UVA Darden. Eric also publishes op-eds on analytics and social justice. You can follow him on LinkedIn.



Notifications
Pingback: The Quant’s Dilemma: Subjectivity In Predictive AI’s Value - RevTech